סעיף א’
import pandas as pd
import matplotlib.pyplot as plt
def read_documents(filename):
table = pd.read_csv(filename)
print(table.head(10))סעיף ב’
def unique_chars(string):
unique = []
for i in range(len(string)):
if string[i] == ' ': continue
if string[i] not in unique:
unique.append(string[i])
return unique
def score(query,doc):
unique = unique_chars(query)
unique_sum = 0
doc_length = len(doc)
for i in range(len(doc)):
if doc[i] == ' ': doc_length -= 1
for j in range(len(unique)):
if unique[j] == doc[i]: unique_sum += 1
return round(unique_sum/doc_length, 3)
ה-string שמקבלת הפונקציה unique_chars(string) או בהתאמה, המשתנה query שמקבלת הפונקציה score(query, doc). כלומר,
ה-doc, המחרוזת אליה משווים את ה-query. כלומר,
המימוש עומד בסיבוכיות הנדרשת כי:
- בפונקצייה
unique_chars(string)התוכנה עוברת על אורך כל המחרוזת באורךפעם אחת. כל פעם שהיא עוברת על המחזורת, היא בודקת אם התו שעוברים אליו נמצא ב- unique, שהוא לכל היותר גם בעל אורך. (למען האמת, הוא לכל היותר בעל אורך של גודל הטבלת Unicode, אבל לצורך השאלה נתעלם מזה). אז קיבלנו סיבוכיות: כלומר, היא עומדת בסיבוכיות הנדרשת. - בפונקצייה
score(query,doc), אנו קוראים פעם אחת לפונקצייהunique_chars(string), כלומר, כבר יש לנו סיבוכיות של לפחות. לאחר מכן עבור כל ערך ב- doc, כלומרפעמים, אנו עוברים על כל הערכים שב- unique, שכמותם לא יכולה להיות גדולה מ-. כלומר:
סעיף ג’
def unique_chars_update(string):
unique = []
for i in range(len(string)):
char = string[i]
if 65 <= ord(char) <= 90: char = chr(ord(char) + 32)
if ord(char) not in range(97, 123): continue
if char not in unique: unique.append(char)
return unique
def score_update(query,doc):
unique = unique_chars_update(query)
unique_sum = 0
doc_length = len(doc)
for i in range(len(doc)):
char = doc[i]
if char == ' ': doc_length -= 1
if 65 <= ord(char) <= 90: char = chr(ord(char) + 32)
if ord(char) not in range(97, 123): continue
for j in range(len(unique)):
if unique[j] == char: unique_sum += 1
return round(unique_sum/doc_length, 3)ביחס לשאלה הקודמת, unique_chars_update(string) , הסיבוכיות שלנו קטנה. כעת אנו עדיין עוברים על כל אורך ה-string, כלומר unique שלנו יכל להיות לכל היותר 26, כלומר מספר קבוע. אזי:
עבור הפונקציה score_update(query, doc), הסיבוכיות גם כן קטנה. אנו קוראים לפונקציה unique_chars_update(), ככה שאנו מתחילים מסיבוכיות doc, כלומר unique[] - לכל היותר 26, שזה קבוע. אז:
סעיף ד’
def histogram(doc):
abc_count = [0]*26
unique = []
for i in range(len(doc)):
char = doc[i]
if 65 <= ord(char) <= 90: char = chr(ord(char) + 32)
if ord(char) not in range(97, 123): continue
char_normalized = ord(char) - 97
abc_count[char_normalized] += 1
abc_list = [chr(i) for i in range(ord('a'), ord('z')+ 1)]
plt.bar(abc_list, abc_count)
plt.show()
def search_engine(query,filename):
table = pd.read_csv(filename)
best_match = [0, "", ""]
for i,doc in enumerate(table["Content"]):
score = score_update(query, doc)
if (score > best_match[0]):
best_match[0] = score
best_match[1] = table["Document_ID"][i]
best_match[2] = doc
print(f"Search Engine retrieved document: {best_match[1]}")
print(best_match[2])
print(f"Score = {best_match[0]}")
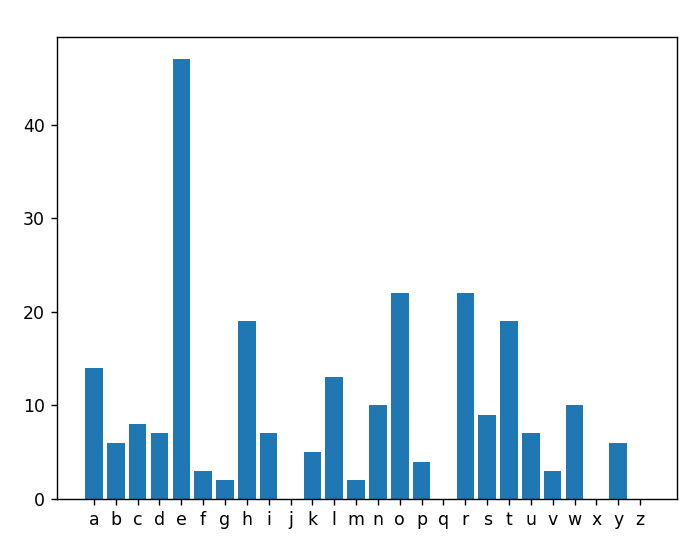
print(histogram(best_match[2]))הרצה ראשונה
עבור:
query = 'The cab arrived late'
filename = "documents.csv"
search_engine(query, filename)מקבלים:
Search Engine retrieved document: Doc #10
The cab arrived late. The inside was in as bad of shape as the outside which was concerning, and it didn't appear that it had been cleaned in months. The green tree air-freshener hanging from the rearview mirror was either exhausted of its scent or not strong enough to overcome the other odors emitting from the cab. The correct decision, in this case, was to get the hell out of it and to call another cab, but she was late and didn't have a choice.
Score = 0.673
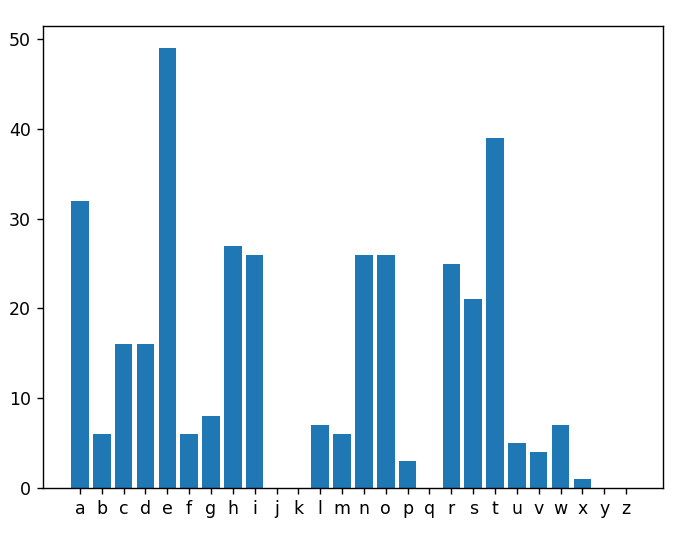
הרצה שנייה
עבור:
query = 'Breastfeeding'
filename = "documents.csv"
search_engine(query,filename)מקבלים:
Search Engine retrieved document: Doc #35
Breastfeeding is good for babies and moms. Infants that are breastfed get antibodies from their mothers against common illnesses. Breastfed babies have less chance of being obese as an adult. Breastfeeding a baby lets the infant-mother pair bond in a very unique way. Mother’s who breastfeed lower their chances of developing breast cancer. Usually, mothers who breastfeed lose their pregnancy weight more quickly and easily. The benefits of breastfeeding are numerous.
Score = 0.722
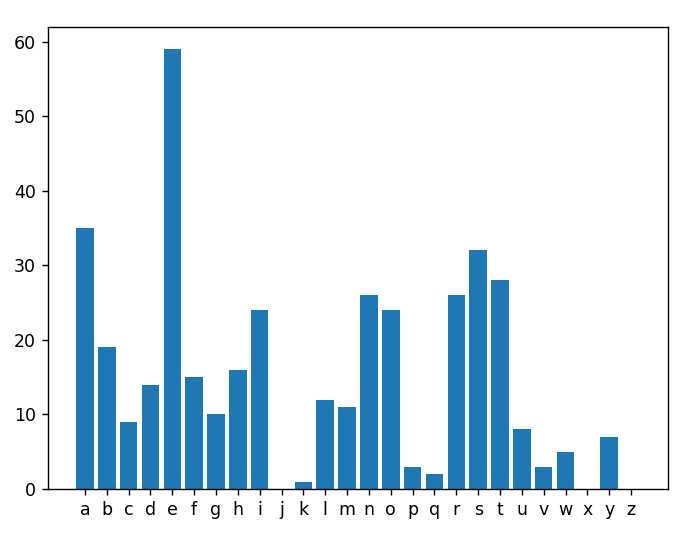
הרצה שלישית
עבור:
query = 'dark grey blue'
filename = "documents.csv"
search_engine(query,filename)מקבלים:
Search Engine retrieved document: Doc #25
It was easy to spot her. All you needed to do was look at her socks. They were never a matching pair. One would be green while the other would be blue. One would reach her knee while the other barely touched her ankle. Every other part of her was perfect, but never the socks. They were her micro act of rebellion.
Score = 0.51